Sudha Subramanian (Self-motivated & Data-Driven)
Projects Portfolio
Safety Monitor
Safety Monitor is a tool, that uses Object Detection using YOLOv3 and Deep Learning on the Edge to monitor safety of workers at construction sites. This tool can be deployed at sites and can take in video streams from a camera, process and alert a supervisor when it finds workers who are not wearing their personal protective equipment.
Here’s a sample of how well our model performed. The image on the left with red bounding boxes show the ground truth, while the image on the right with teal bounding boxes show the actual predicions from our model.

Learn more about this project at Safety Monitor
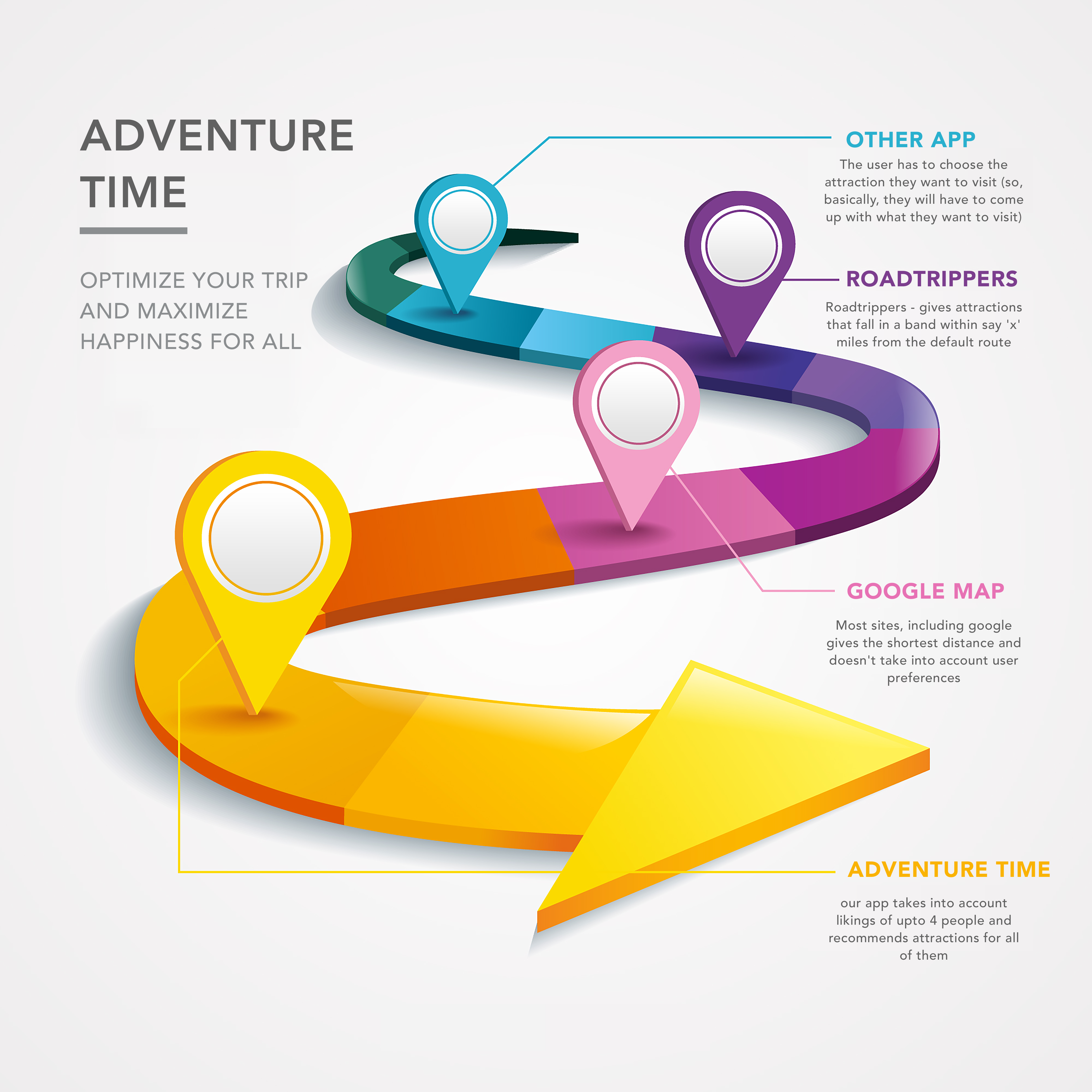
Adventure Time
Adventure Time is a tool that can help plan your next road trip. This is a live web app, that leverages a large publicly available dataset of businesses in the US, with location and (preferably) rating information. It can take in user preferences for up to four people and provide an optimized itinerary, based on what the user input about the length of the road trip and ratings of various categories of attractions.
It helps you plan a road trip between two US cities, for up to four people with varied interests. It also balances the interests of the group and takes into account the amount of driving you want to do each day. The tool presents you a proposed route with a list of interesting and fun attractions and provides the options to customize based on your interests. Once you finalize the route, it displays a final itinerary with suggestions for restaurants and accommodation along the way.
Do check out Adventure Time and plan your next road trip with us!
The infographic shown below captures why you need Adventure Time compared to other apps.
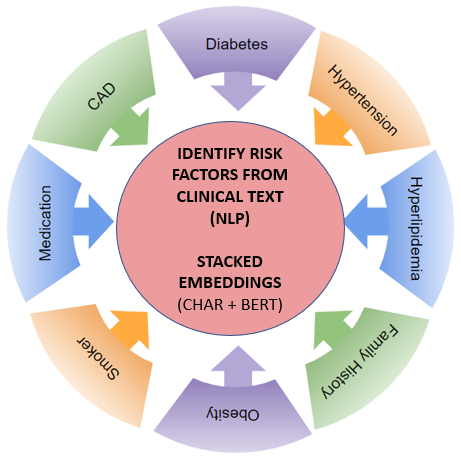
Identify Heart Disease Risk Factors from Clinical Notes
NLP (Natural Language Processing) is a specialized aspect of Machine Learning that deals with text data mining and handling. It is certainly one of the most challenging tasks within the field of Machine Learning and Data Science. Our task was to identify risk factors for heart disease from clinical text. There is wealth of information in clinical text, that can be leveraged using NLP and Deep Learning techniques. This work proposes a novel way of using stacked embeddings, as a way to improve on work that has already been done in this space as part of i2b2 2014 challenge.
This involved several approaches, building multiple models and leverage the power of BERT pre-trained models and training them on Google Cloud TPU. One of the aspects we focused on was the nature of the data and how both character embedding and BERT Embedding (for its contextual embedding) would work together. So, by stacking embeddings, (conceptually a way to combine multiple embeddings), we were able to obtain excellent results on the i2b2 heart disease risk factors challenge dataset. For this, we used Flair package and stacked BERT and character embeddings (BERT-CHAR Embedding), as well as PubMed (forward and backward) embeddings.
Learn more about this project at Heart Disease - Identify Risk Factors
FoodFlix: Food Recommender App
Built a food recommender app (MVP) that can taken in user preferences and use that information to recommend new recipes. The data for this was scraped from ‘allrecipes.com’ and users were prompted to like / dislike a handful of them to gather user’s likings / preferences.
Check out the app at FoodFlix - Netflix for Food
Facial Keypoint Detection
Used advanced Deep Learning techniques such as Transfer Learning and Ensemble methods to detect facila keypoints (using Kaggle dataset). One of the key challenges was limited availability of data for building our DL model. So, we applied image augmentation techniques such as rotation, reflection, horizontal flipping, histogram equalization, blurring etc. to get additional training data. We experimented on various architectures including AlexNet, VGGNet as well as tried different activation functions such as ReLu, LeakyReLU. With hyperparameter tuning, transfer learning and ensemble approach, our results scored an equivalent of rank #16 on Kaggle’s private leaderboard.
Check out the code at our Github page at Facial Keypoint Detection
Research Paper
Co-authored a research paper titled “A stochastic model for automated teller machines subject to catastrophic failures and repairs” with Prof. Chakravarthy, Kettering University (Flint, MI), which has been submitted for publication. The study applies queuing theory and models arrival of customers as Markovian arrival process (MAP) with a phase-type distribution; analysis of outcomes under different conditions and interpretation through visualizations in R
Learn more details at Stochastic Model - ATM Failures
Presentation at Conference
Performed a case study across multiple datasets to show how accuracy of models can be enhanced by applying clustering techniques across various modeling techniques. Datasets include:
- Predict Medicare reimbursement costs
- Predict Increase in Solar Energy Generation
- Predict increase / decrease in Stock prices
Presented the findings as a paper titled “Comparing Accuracy of Models Built on Subpopulation vs. Entire Population” at the 2016 International Conference on Business Analytics and Intelligence, India.
Learn more details at Cluster Then Predict - Case Study
Enjoy reading!